
- 분류 전체보기 (91)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 6주차후기
- 스터디
- 혼공머신
- 스터디완료
- 맛있는디자인스터디12기
- Doit파이썬스터디
- CS2023
- 혼공단
- 전면개정2판
- 생성형AI
- 맛있는디자인스터디13기
- 진짜쓰는일러스트레이터
- 맛있는디자인
- 혼공JS
- CC2023
- 혼공학습단
- 맛있는디자인스터디11기
- 혼공파
- 애프터이펙트
- 프리미어프로
- Doit점프투파이썬
- 혼공자
- 혼공
- 혼공C
- 3주차후기
- 회고
- 제이펍
- 후기
- 혼공분석
- 챌린지
- Today
- Total
애독자's 공부방
[혼공분석] 3주차 _ 혼자 공부하는 데이터 분석 with 파이썬 본문
혼공단 - 혼공분석, 혼자 공부하는 데이터 분석 with 파이썬
■ 공부한 내용
| # | 진도 | 기본 숙제(필수) | 추가 숙제(선택) |
| 3주차 (1/20 ~ 1/26) |
Chapter 03 | p. 182의 확인 문제 2번 풀고 인증하기 | p. 219의 확인 문제 5번 풀고 인증하기 |

□ Chapter 03 | 데이터 정제하기
▷ 03-1 | 불필요한 데이터 삭제하기
1. 핵심 포인트 요약
- 데이터 정제(data cleaning): 수집된 데이터에서 잘못된 부분을 고치거나 제거하여 필요한 데이터를 준비하는 과정
. 데이터가 올바르게 정제되지 못하면 분석된 결과를 왜곡시킬 수 있으며 잘못된 의사 결정을 초래하기도 함
- 데이터 랭글링(data wrangling) 또는 데이터 먼징(data munging): 데이터를 정제하고 데이터 분석 및 머신러닝에 적합한 형태로 데이터를 변환하는 과정
. 데이터의 품질을 높이고 필요한 형식으로 준비하는 데 중요한 역할을 수행
- 원소별 비교(element-wise comparison): 판다스의 데이터프레임과 인덱스를 하나의 값과 비교하면 데이터프레임과 인덱스에 있는 모든 원소와 비교하는 과정
. 비교한 결과는 True 또는 False로 이루어진 불리언 배열로 반환
- 넘파이 배열(Numpy array): 파이썬의 대표적인 다차원 배열로, 판다스의 데이터프레임과 달리 한 종류의 데이터만 담을 수 있지만 매우 효율적이고 성능이 높음
. 파이썬의 다른 과학 패키지와 호환성이 높으며 기본 데이터 구조로 널리 사용
2. 책에 나온 함수와 메서드
| 함수/메서드 | 기능 | 사용 |
| DataFrame.drop() | 데이터프레임의 행이나 열을 삭제 | DataFrame.drop(labels, axis, inplace) |
| . 매개변수: 설명 | ||
| . labels: 삭제하려는 행 인덱스나 열 이름을 전달. 리스트로 전달하면 여러 개의 행을 삭제 가능 . axis: 삭제할 축을 지정 (기본값: 0으로 행을 삭제 / 1로 지정하면 열을 삭제) . inplace: 기본값은 False로 삭제 결과를 반환. True로 설정하면 현재 데이터프레임 자체를 변경 |
||
| DataFrame.dropna() | 누락된 값이 포함된 행이나 열을 삭제 | DataFrame.dropna(axis, how, thresh, subset, inplace) |
| . axis: 삭제할 축을 지정 (기본값: 0으로 행을 삭제 / 1로 지정하면 열을 삭제) . how: 삭제할 기준을 지정 (기본값: 'any'로 누락된 값이 하나 이상이면 삭제 / 'all'로 지정하면 모든 원소가 누락된 행이나 열을 삭제) . thresh: 최소한의 누락되지 않은 값의 개수를 지정. 이를 지정하면 how 매개변수에 상관없이 누락되지 않은 값의 개수가 thresh 보다 작은 행과 열을 삭제 . subset: 삭제할 행과 열 리스트를 지정. 행을 삭제하는 경우에는 열 인덱스를 지정하고 열을 삭제할 때는 행 이름을 지정 . inplace: 기본값은 False이며 삭제한 결과를 반환. True는 현재 데이터프레임 자체를 변경 |
||
| DataFrame.duplicated() | 중복된 행을 찾아 불리언 값으로 표시한 배열을 반환 | DataFrame.duplicated(subset, keep) |
| . subset: 중복 검사를 위해 고려할 열 이름 또는 열 이름의 리스트를 지정. 지정하지 않으면 전체 열을 대상으로 중복을 검사 . keep: 중복된 행을 표시할 방법을 결정. (기본값: 'first'는 처음 등장하는 행을 제외하고 나머지 중복된 행을 True로 표시 / 'last'로 지정하면 마지막으로 등장하는 행을 제외하고 나머지 중복된 행을 True로 표시 / False로 지정하면 중복된 모든 행을 True로 표시 |
||
| DataFrame.groupby() | 데이터프레임의 행을 그룹으로 모음 | DataFrame.groupby(by, dropna) |
| . by: 그룹으로 묶을 기준이 되는 열 또는 열 이름의 리스트를 전달 . dropna: 기본값은 True이며 by 매개변수에 지정된 열에 누락된 값이 있는 행을 제외. False로 지정하면 누락된 값도 대상 |
||
| DataFrame.sum() | 행 또는 열을 기준으로 합계를 계산 | DataFrame.sum(axis, skipna) |
| . axis: 합계를 계산할 축을 지정 (기본값: 0은 열마다 합계를 계산 / 1은 행마다 합계를 계산) . skipna: 기본값은 True이며 누락된 값은 제외하고 계산. False로 지정하면 누락된 값이 있는 경우 NaN를 반환 |
||
| DataFrame.set_index() | 지정한 열을 인덱스로 설정 | DataFrame.set_index(keys, drop, append, inplace) |
| . keys: 인덱스로 지정할 열 또는 열 리스트를 전달 . drop: 기본값은 True이며 인덱스로 지정한 열을 삭제하고 인덱스에 추가. False면 열을 미삭제 . append: 기본값은 False이며 기존에 인덱스에 미추가. True로 지정하면 기존의 인덱스에 새로운 인덱스 열을 추가 . inplace: 기본값은 False이며 변경된 결과를 반환. True이면 현재 데이터프레임 자체를 변경 |
||
| DataFrame.reset_index() | 데이터프레임의 인덱스를 재설정 | DataFrame.reset_index(level, drop, inplace) |
| . level: 인덱스에서 제거할 열 이름 또는 순서를 지정. 가장 왼쪽의 첫 번째 인덱스의 순서가 0. 이 매개변수를 지정하지 않으면 전체 인덱스를 재설정 . drop: 기본값은 False이며 인덱스에서 제외된 열을 데이터프레임 열로 이동. True이면 데이터프레임 열로 이동하지 않고 삭제 . inplace: 기본값은 False이며 변경된 결과를 반환. True이면 현재 데이터프레임 자체를 변경 |
||
| DataFrame.update() | 다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트. 다른 데이터프레임에 있는 NaN는 업데이트에서 제외 | DataFrame.update(other, overwrite) |
| . other: 업데이트에 사용할 데이터프레임을 지정 . overwrite: 원본 데이터프레임의 업데이트 방식을 지정. 기본값 True는 원본 데이터 프레임에 있는 모든 값을 업데이트. False는 원본 데이터프레임에 있는 NaN만 업데이트 |
||
| DataFrame.equals() | 다른 데이터프레임과 동일한 원소를 가졌는지 비교. 두 데이터프레임이 동일하면 True, 그렇지 않으면 False를 반환 | DataFrame.equals(other) |
| . other: 비교하려는 데이터프레임을 전달. 두 데이터프레임이 동일하면 True. 아니면 False 반환 | ||
▷ 03-2 | 잘못된 데이터 수정하기
1. 핵심 포인트 요약
- NaN(Not a Number): 판다스에서 누락된 값을 표시하는 기호
. isna() 메서드를 사용하여 NaN의 여부를 확인하거나, notna() 메서드를 사용해 NaN이 아닌 값인지 체크 가능
- 정규 표현식(regular expression): 문자열에서 패턴을 찾고 대체하기 위한 규칙의 모음
. 정규 표현식을 사용하면 복잡한 패턴을 가진 문자열을 쉽게 검색 가능
2. 책에 나온 함수와 메서드
| 함수/메서드 | 기능 | 사용 |
| DataFrame.info() | 데이터프레임의 요약 정보를 출력 | DataFrame.info(memory_usage, show_counts) |
| . 매개변수: 설명 | ||
| . memory_usage: 기본값은 True이며 열의 데이터 타입과 행 개수로 메모리 사용량을 추정. False면 메모리 사용량을 미출력. 'deep'으로 설정하면 실제 메모리 사용량을 계산. . show_counts: 기본값은 True이며 누락되지 않은 원소 개수를 출력. False면 누락되지 않은 원소 개수를 미출력 |
||
| DataFrame.isna() | 누락된 값을 감지하는 메서드로 셀의 값이 None이나 NaN일 경우 True를 반환 | DataFrame.isna() |
| DataFrame.astype() | 데이터 타입을 지정 | DataFrame.astype(dtype) |
| . dtype: 데이터 타입을 지정하면 데이터프레임의 모든 열에 적용. 딕셔너리를 전달하면 특정 열의 데이터 타입을 변경 가능 | ||
| DataFrame.fillna() | 데이터프레임에서 누락된 원소의 값을 채움 | DataFrame.fillna(value, method, axis, inplace) |
| . value: 전달할 값이 스칼라인 경우 데이터프레임에서 누락된 값을 해당 값으로 채움. {열 이름: 채울 값} 형식의 딕셔너리인 경우 열마다 '채울 값'으로 누락된 값을 채움. 데이터프레임인 경우 누락된 원소의 열과 인덱스에 해당하는 데이터프레임 원소로 채움. 이 매개변수를 지정하지 않으면 method 매개변수로 누락된 값의 앞뒤에 있는 값으로 채움 . method: 'bfill' 또는 'backfill'로 지정하면 누락된 값 이후에 등장하는 유효한 값으로 현재 누락된 값을 채움. df.fillna(method='ffill')은 df.ffill()와 동일. 'ffill' 또는 'pad'는 누락된 값 이전에 등장하는 유효한 값으로 현재 누락된 값을 채움. df.fillna(method='bfill')은 df.bfill()와 동일 . axis: method 매개변수와 함께 지정. 기본값 0은 행 방향으로 누락된 값을 채움. 1은 열 방향으로 누락된 값을 채움. 이때 method가 'bfill'이면 오른쪽 열의 값으로 왼쪽을, 'ffill'은 왼쪽 열의 값으로 오른쪽 열을 채움 . inplace: 기본값은 False이며 삭제된 결과를 반환. True로 설정하면 현재 데이터프레임 자체를 변경 |
||
| DataFrame.replace() | 데이터프레임의 값을 다른 값으로 변경 | DataFrame.replace(to_replace, value, inplace, regex) |
| . to_replace: 찾을 값이 정수나 문자열, 정규 표현식인 경우 데이터프레임에서 값을 찾아 value 매개변수 값으로 변경. 정수나 문자열, 정규 표현식의 리스트인 경우 값을 찾아 value의 값으로 변경. 이 매개변수와 동일한 길이의 리스트라면 동일한 위치에 있는 값으로 변경. {열 이름: 찾을 값} 형식이면 지정한 열에서 '찾을 값'을 value 매개변수의 값으로 변경. {열 이름: {찾을 값: 새오룬 값}} 형식이면 지정한 열에서 '찾을 값'을 '새로운 값'으로 변경 . value: 찾을 값이 정수나 문자열, 정규 표현식 또는 정규 표현식의 리스트인 경우 대체할 값 . inplace: 기본값은 False며 삭제된 결과를 반환. True이면 현재 데이터프레임 자체를 변경 . regex: 기본값은 False며 정규 표현식의 사용 불가. True이면 정규 표현식 사용 가능 |
||
| Series.str.contains() | 시리즈나 인덱스에서 문자열 패턴을 포함하고 있는지 검사 | Series.str.contains(pat, case, na, regex) |
| . pat: 찾을 문자열 또는 정규 표현식 . case: 기본값은 True이며 대소문자를 구분. False로 지정하면 대소문자 미구분 . na: 누락된 값을 가진 원소에 채울 값을 지정. 기본 np.nan을 사용 . regex: 정규 표현식을 사용할지 결정 (기본값: True) |
||
| DataFrame.gt() | 데이터프레임의 원소보다 큰 값을 검사 | DataFrame.gt(other, axis) |
| . other: 비교하려는 값 . axis: 비교하는 방향을 지정. 기본값 1은 열 방향으로 비교. 0은 행 방향으로 비교 |
||
■ 기본 숙제
▷ p. 182의 확인 문제 2번 풀고 인증하기
- 정답: ④
. 3번째 열이 True므로 'col1'이 아닌 'col3'이 선택되기에, 'col3'의 합을 계산하게 된다.

■ 추가 숙제(선택)
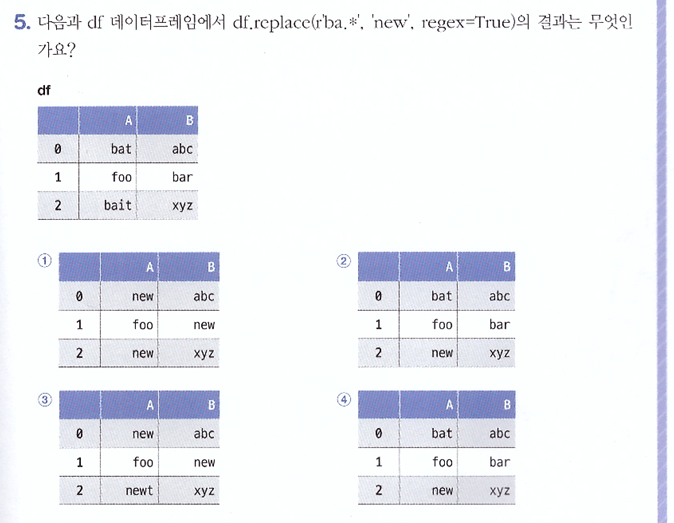
▷ p. 219의 확인 문제 5번 풀고 인증하기
- 정답: ①
. r'ba.*'의 경우 'ba'로 시작하면서 그 이후에 어떤 문자든지 0개 이상 올 수 있다는 의미로, ba로 시작하는 모든 문자열을 포함
. 이후 위 정규 표현식으로 찾은 패턴에 해당하는 값을 'new'로 대체하기에, 'bat'와 'bait'가 모두 'new'로 변경됨
'데이터분석 > 혼공학습단 13기' 카테고리의 다른 글
| [혼공분석] 2주차 _ 혼자 공부하는 데이터 분석 with 파이썬 (1) | 2025.01.13 |
|---|---|
| [혼공분석] 1주차 _ 혼자 공부하는 데이터 분석 with 파이썬 (2) | 2025.01.08 |

